월마트, 우버는 어떻게 수요를 예측할까? 딥러닝 기반 시계열 예측 AI - Temporal Fusion Transformer
유튜브 영상 : https://youtu.be/3olZYmkdp-Y
1. 기업 활용 사례 및 필요성
1.1 TFT를 활용하는 기업 및 서비스
Temporal Fusion Transformer(TFT)는 현재 다양한 글로벌 기업들에서 시계열 예측을 위해 활발히 사용되고 있습니다:
- Amazon: 재고 관리 및 수요 예측에 TFT를 활용하여 공급망 최적화
- Google: 클라우드 서비스에서 AI Platform의 일부로 TFT 기반 예측 서비스 제공
- Uber: 승차 수요 예측 및 가격 책정에 TFT 모델 활용
- 월마트: 매장별 재고 관리 및 판매 예측에 적용
- Netflix: 콘텐츠 인기도 예측 및 서버 리소스 할당에 활용
- 금융기관: 주가 및 자산 가격 예측을 위한 모델로 활용
1.2 기업이 TFT를 도입해야 하는 이유
1) 복잡한 시계열 패턴 포착 능력
- 전통적인 시계열 모델(ARIMA, ETS 등)이나 단순 RNN 기반 모델보다 복잡한 시간적 의존성 패턴을 더 정확하게 포착
- 계절성, 트렌드, 변동성 등 다양한 시계열 특성을 동시에 학습 가능
2) 다변량 시계열 데이터 처리
- 여러 변수 간의 복잡한 관계를 모델링할 수 있어 비즈니스 환경에서 다양한 요인을 고려한 예측 가능
- 정적 변수(static), 과거 변수(known), 미래 변수(unknown)를 구분하여 처리하는 유연한 아키텍처
3) 해석 가능성(Interpretability)
- 블랙박스 모델이 아닌, 어텐션 메커니즘을 통해 어떤 변수와
시점이 예측에 중요한지 시각화 가능 - 의사결정자에게 예측 근거 제공으로 신뢰성 향상
4) 불확실성 정량화
- 점(point) 예측뿐만 아니라 예측 구간(prediction intervals)을 제공하여 리스크 관리에 유용
- 다양한 시나리오 계획 수립 가능
5) 장기 예측 성능
- 단기 예측뿐만 아니라 장기 예측에서도 우수한 성능을 보임
- 다단계(multi-horizon) 예측에 최적화된 구조
6) 데이터 효율성
- 적은 데이터로도 효과적인 학습이 가능한 구조
- 변수 선택 메커니즘으로 불필요한 정보 필터링
이러한 장점들로 인해 수요 예측, 가격 예측, 리소스 할당, 이상 탐지 등 다양한 비즈니스 문제에 TFT가 적합한 솔루션으로 자리잡고 있습니다.
2. TFT의 등장 배경과 개발 동기
2.1 시계열 예측의 진화
시계열 예측 기술은 다음과 같은 단계를 거쳐 발전해왔습니다:
- 전통적인 통계 모델 (1970-2000년대)
- ARIMA, ETS, VAR 등 통계 기반 모델
- 한계: 선형 관계 위주 모델링, 복잡한 패턴 포착 어려움
- 머신러닝 도입 시기 (2000-2015)
- Random Forest, Gradient Boosting 등 적용
- 한계: 시간적 의존성 명시적 처리 부족
- 초기 딥러닝 시기 (2015-2018)
- RNN, LSTM, GRU 등 순환신경망 적용
- 한계: 장기 의존성 처리 어려움, 해석성 부족
- 어텐션 기반 시대 (2018-현재)
- Transformer 아키텍처 기반 모델 등장
- TFT는 이 흐름의 대표적 모델 (Google, 2019)
2.2 TFT 개발의 필요성
기존 시계열 예측 모델들은 다음과 같은 한계를 가지고 있었습니다:
- 정적/동적 특성 통합 문제
- 기존 모델들은 시간에 따라 변하는 변수와 고정된 변수를 효과적으로 통합하기 어려웠음
- 예: 제품 카테고리(정적)와 일별 가격 변동(동적) 정보 통합 모델링 문제
- 다양한 시간 스케일 처리 한계
- 일, 주, 월 등 다양한 시간적 패턴을 동시에 모델링하기 어려웠음
- 해석 가능성 부족
- 딥러닝 모델의 블랙박스 특성으로 인한 신뢰성 및 활용성 저하
- 불확실성 정량화 미흡
- 예측의 불확실성을 정확히 측정하기 어려워 리스크 관리에 한계
- 다변량/다단계 예측의 어려움
- 여러 변수에 대한 장기 예측 성능 한계
2.3 TFT의 탄생
이러한 문제들을 해결하기 위해 2019년 Google Research 팀(Bryan Lim, Sercan Arik, Nicolas Loeff, Tomas Pfister)은 "Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting"이라는 논문을 통해 TFT를 발표했습니다.
TFT는 다음과 같은 혁신적 특징을 갖추도록 설계되었습니다:
- 다양한 유형의 입력 변수(정적, 과거 알려진, 미래 알려진)를 효과적으로 처리
- LSTM 기반 인코더-디코더 구조와 자기 주의(self-attention) 메커니즘의 결합
- 변수 선택 레이어를 통한 중요 변수 자동 식별
- 다단계 예측을 위한 특화된 구조
- 확률적 예측을 통한 불확실성 정량화
3. TFT의 아키텍처와 동작 방식
3.1 TFT 아키텍처 개요
TFT는 다음과 같은 주요 구성 요소로 이루어져 있습니다:
입력 데이터 → 입력 변환 레이어 → 변수 선택 네트워크 → LSTM 인코더 → LSTM 디코더 →
시간적 자기 주의 메커니즘 → 위치별 피드 포워드 네트워크 → 양방향 출력 레이어 → 예측값아키텍처 다이어그램:
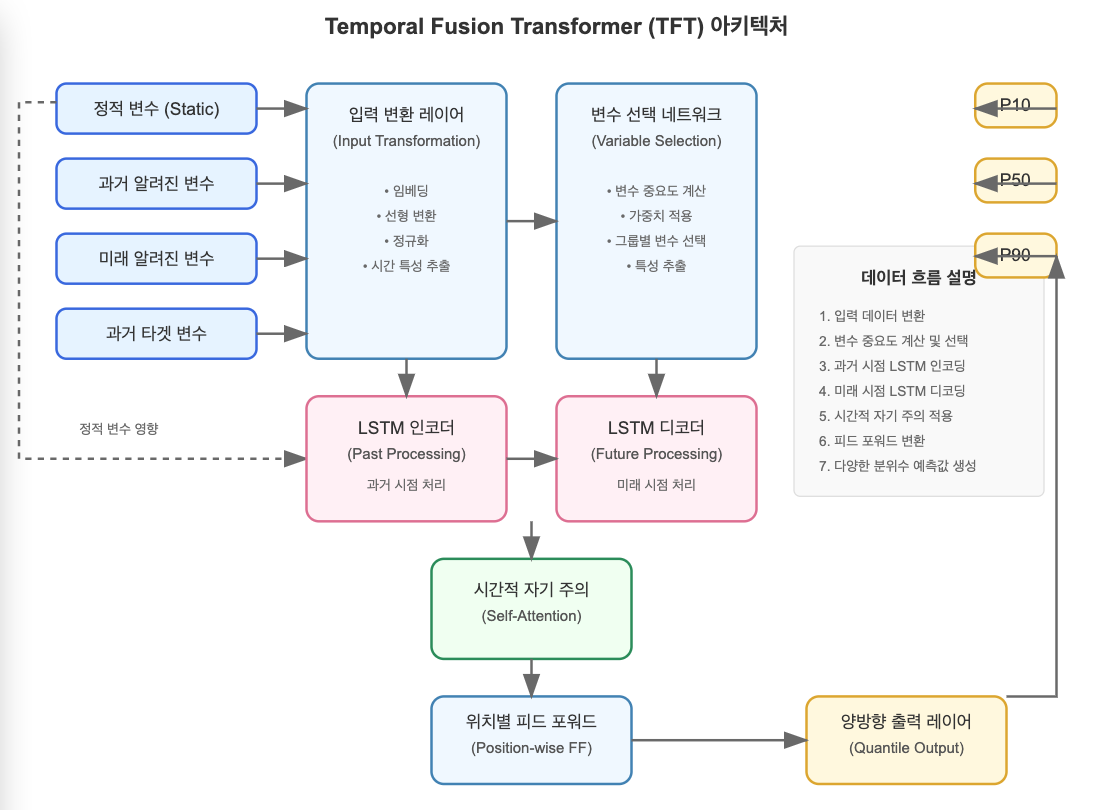
TFT 아키텍처의 주요 구성 요소:
- 입력 변환 레이어 (Input Transformation)
- 정적 변수(제품 카테고리 등), 과거 시간 의존 변수(과거 판매량 등), 미래 알려진 변수(휴일 여부 등)를 각각 별도로 처리
- 범주형 변수는 임베딩으로, 연속형 변수는 선형 변환으로 처리
- 변수 선택 네트워크 (Variable Selection Network)
- 각 변수 그룹(정적, 과거, 미래)에 대해 중요도 가중치 계산
- 예측에 중요한 변수를 자동으로 선별하는 기능
- 시계열 인코딩 레이어 (Temporal Processing)
- LSTM 기반 인코더: 과거 시점의 시계열 데이터 처리
- LSTM 기반 디코더: 미래 시점의 예측 수행
- 양방향이 아닌 단방향 LSTM 사용으로 인과성 보존
- 시간적 자기 주의 메커니즘 (Temporal Self-Attention)
- 서로 다른 시점 간의 관계를 직접 모델링
- 장기 의존성 패턴 식별 (예: 1년 전 같은 시즌의 판매 패턴과 현재 패턴 연결)
- 멀티헤드 어텐션 기법 적용
- 위치별 피드 포워드 네트워크 (Position-wise Feed-forward Network)
- 각 시점의 특성을 독립적으로 변환하는 층
- 게이트 메커니즘을 통한 정보 흐름 제어
- 잔차 연결(residual connection)을 통한 그래디언트 소실 방지
- 양방향 출력 레이어 (Quantile Output Layer)
- 다양한 분위수(예: 10%, 50%, 90%)에 대한 예측값 생성
- 예측의 불확실성을 정량화하여 신뢰 구간 제공
이 구성 요소들이 함께 작동하여 TFT는 시계열 예측에 필요한 복잡한 패턴을 효과적으로 포착하고, 예측 결과에 대한 해석 가능성을 제공합니다.
3.2 입력 데이터 유형 구분
TFT의 가장 큰 특징 중 하나는 입력 데이터를 세 가지 유형으로 명확히 구분한다는 점입니다:
- 정적 변수 (Static Covariates)
- 시간에 따라 변하지 않는 특성
- 예: 제품 카테고리, 고객 세그먼트, 매장 위치 등
- 시간에 무관하게 전체 예측에 영향을 미침
- 과거 시간 의존 변수 (Past Time-dependent Covariates)
- 과거에만 알 수 있는 시간에 따라 변하는 특성
- 예: 과거 판매량, 과거 가격, 과거 트래픽 등
- 예측 시점에서는 미래 값을 알 수 없음
- 미래 알려진 변수 (Future Time-dependent Covariates)
- 미래에도 알 수 있는 시간 변수
- 예: 휴일 여부, 프로모션 일정, 요일 등
- 예측 시점에서 미래 값을 알고 있음
3.3 TFT의 주요 구성 요소별 작동 방식
3.3.1 입력 변환 레이어 (Input Transformation)
각 유형의 입력 변수는 서로 다른 처리 경로를 거칩니다:
입력 데이터 → 임베딩 레이어 → 선형 변환 → 표준화- 범주형 변수: 임베딩을 통해 저차원 벡터로 변환
- 연속형 변수: 선형 변환 및 정규화
- 시간 특성: 특별한 시간 특성 추출 (예: 요일, 월, 휴일 등)
3.3.2 변수 선택 네트워크 (Variable Selection Network)
변수 선택 네트워크는 다음 과정을 통해 중요 변수를 식별합니다:
- 입력 변수 각각에 대해 가중치 계산
- 중요하지 않은 변수는 가중치를 낮게 부여
- 정적, 과거, 미래 변수 각 그룹에 대해 별도의 변수 선택 네트워크 적용
# 변수 선택 네트워크의 개념적 구현
def variable_selection_network(inputs, hidden_layer_size):
# 변수별 처리
transformed_inputs = []
for var in inputs:
# 각 변수에 대한 처리
grn_output = gated_residual_network(var)
transformed_inputs.append(grn_output)
# 변수 중요도 가중치 계산
concat_inputs = tf.concat(transformed_inputs, axis=-1)
weights = softmax_layer(concat_inputs)
# 가중치 적용
combined_inputs = sum([weights[i] * transformed_inputs[i] for i in range(len(inputs))])
return combined_inputs, weights3.3.3 LSTM 기반 시계열 처리 (Temporal Processing)
과거 시점과 미래 시점의 처리는 다음과 같이 이루어집니다:
- 인코더 LSTM: 과거 시점의 시계열 처리
- 과거 시간 의존 변수와 과거 미래 알려진 변수를 처리
- 과거 컨텍스트 정보 추출
- 디코더 LSTM: 미래 시점의 시계열 처리
- 미래 알려진 변수와 인코더의 마지막 상태를 활용
- 각 예측 시점에 대한 은닉 상태 생성
- 정적 변수 영향: 정적 변수는 LSTM 초기 상태와 게이트 메커니즘에 영향을 줌
3.3.4 시간적 자기 주의 메커니즘 (Temporal Self-Attention)
시간적 자기 주의 메커니즘은 다음과 같은 핵심 기능을 수행합니다:
- 모든 시점 간의 관계를 직접 모델링
- 장기 의존성 패턴 포착
- 다음과 같은 구성 요소로 이루어짐:
- Query, Key, Value 매트릭스
- 멀티헤드 어텐션 메커니즘
- 시간적 마스킹 (미래 정보 누출 방지)
# 시간적 자기 주의 메커니즘의 개념적 구현
def temporal_self_attention(lstm_outputs, num_heads):
# 멀티헤드 어텐션 적용
attention_output = multi_head_attention(
queries=lstm_outputs,
keys=lstm_outputs,
values=lstm_outputs,
num_heads=num_heads
)
# 잔차 연결 및 정규화
attention_output = layer_norm(lstm_outputs + attention_output)
return attention_output3.3.5 위치별 피드 포워드 네트워크 (Position-wise Feed-forward)
각 시점의 특성을 독립적으로 변환하여 비선형성을 추가합니다:
- 각 시점에 동일한 피드 포워드 네트워크 적용
- 게이트 메커니즘을 통한 정보 흐름 제어
- 잔차 연결로 그래디언트 소실 방지
3.3.6 양방향 출력 레이어 (Quantile Output)
불확실성을 정량화하기 위한 양방향 예측을 생성합니다:
- 여러 분위수(예: 10%, 50%, 90%)에 대한 예측값 제공
- 예측 구간을 통한 불확실성 정량화
- 분위수 손실 함수를 통한 학습
3.4 TFT의 핵심 혁신 포인트
- 변수의 독립적 처리: 각 유형의 변수(정적, 과거, 미래)를 독립적으로 처리
- 변수 선택 메커니즘: 예측에 중요한 변수를 자동으로 식별
- 멀티호라이즌 예측: 여러 미래 시점에 대한 동시 예측 수행
- 시간적 자기 주의: 장기 의존성 포착을 위한 어텐션 메커니즘
- 해석 가능성: 변수 중요도와 시간적 어텐션 가중치를 통한 모델 해석 제공
4. 파이썬으로 TFT 구현하기
이 섹션에서는 PyTorch와 PyTorch Forecasting 라이브러리를 사용하여 실제 TFT 모델을 구현하고 훈련해보겠습니다. 전자상거래 판매 예측 시나리오를 가정하여 진행하겠습니다.
4.1 필요한 라이브러리 설치
먼저 필요한 라이브러리를 설치합니다:
# 필요한 라이브러리 설치
!pip install pytorch-forecasting
!pip install pytorch-lightning4.2 데이터 준비
실제와 유사한 전자상거래 판매 데이터를 생성하여 사용하겠습니다:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
import torch
import pytorch_lightning as pl
from pytorch_forecasting import TimeSeriesDataSet, TemporalFusionTransformer
from pytorch_forecasting.metrics import QuantileLoss
from pytorch_lightning.callbacks import EarlyStopping, LearningRateMonitor
from pytorch_lightning.loggers import TensorBoardLogger
# 시드 설정
np.random.seed(42)
torch.manual_seed(42)
# 가상의 전자상거래 판매 데이터 생성
def generate_ecommerce_data(num_products=5, num_days=365):
# 시작 날짜 설정
start_date = datetime(2022, 1, 1)
# 데이터를 저장할 리스트
data = []
# 각 제품별로 데이터 생성
for product_id in range(1, num_products + 1):
# 제품 카테고리 (전자제품=1, 의류=2, 식품=3)
category = np.random.choice([1, 2, 3])
# 제품 가격 범위 (카테고리별로 다른 가격 범위 설정)
if category == 1: # 전자제품
price = np.random.uniform(100, 1000)
elif category == 2: # 의류
price = np.random.uniform(20, 200)
else: # 식품
price = np.random.uniform(5, 50)
# 기본 판매량 트렌드 (제품마다 다른 기본 판매량)
base_sales = np.random.uniform(10, 100)
# 각 날짜별로 데이터 생성
for day in range(num_days):
current_date = start_date + timedelta(days=day)
# 요일 (0=월요일, 6=일요일)
weekday = current_date.weekday()
is_weekend = 1 if weekday >= 5 else 0
# 월 (1-12)
month = current_date.month
# 계절성 효과 (월별)
season_effect = np.sin(2 * np.pi * month / 12) * 0.2
# 주간 계절성 (주말에 판매량 증가)
weekday_effect = 0.3 if is_weekend else 0
# 프로모션 여부 (10% 확률로 프로모션 진행)
promotion = np.random.choice([0, 1], p=[0.9, 0.1])
# 프로모션 효과 (프로모션 시 판매량 50% 증가)
promotion_effect = 0.5 if promotion else 0
# 가격 변동 (기본 가격에서 ±10% 변동)
price_factor = np.random.uniform(0.9, 1.1)
current_price = price * price_factor
# 휴일 여부 (임의로 5% 날짜를 휴일로 지정)
is_holiday = np.random.choice([0, 1], p=[0.95, 0.05])
holiday_effect = 0.4 if is_holiday else 0
# 트렌드 효과 (시간이 지남에 따라 판매량 증가)
trend_effect = day / num_days * 0.5
# 랜덤 노이즈 (±20%)
noise = np.random.uniform(0.8, 1.2)
# 총 판매량 계산
sales = base_sales * (1 + season_effect + weekday_effect + promotion_effect + holiday_effect + trend_effect) * noise
# 재고 수준 (판매량의 몇 배로 설정)
inventory = np.round(sales * np.random.uniform(1.5, 5))
# 결과 저장
data.append({
'date': current_date,
'product_id': product_id,
'category': category,
'price': current_price,
'promotion': promotion,
'is_weekend': is_weekend,
'is_holiday': is_holiday,
'month': month,
'inventory': inventory,
'sales': sales
})
# 데이터프레임으로 변환
df = pd.DataFrame(data)
return df
# 가상 데이터 생성
df = generate_ecommerce_data(num_products=5, num_days=365)
# 시계열 인덱스 생성
df['time_idx'] = df.groupby('product_id')['date'].transform(lambda x: (x - x.min()).dt.days)
# 날짜를 문자열로 변환
df['date'] = df['date'].dt.strftime('%Y-%m-%d')
# 데이터 확인
print(df.head())4.3 데이터 전처리 및 특성 정의
TFT 모델을 위해 데이터를 전처리하고 변수 유형을 정의합니다:
# 훈련/검증 데이터 분할
train_data = df[df['time_idx'] <= 300]
val_data = df[(df['time_idx'] > 300) & (df['time_idx'] <= 365)]
# 최대 예측 길이
max_prediction_length = 7 # 7일 예측
# 최대 인코더 길이
max_encoder_length = 30 # 30일 과거 데이터 사용
# 훈련 데이터셋 정의
training_dataset = TimeSeriesDataSet(
data=train_data,
time_idx="time_idx",
target="sales",
group_ids=["product_id"],
min_encoder_length=max_encoder_length // 2, # 인코더 최소 길이
max_encoder_length=max_encoder_length,
min_prediction_length=1,
max_prediction_length=max_prediction_length,
static_categoricals=["product_id", "category"], # 정적 범주형 변수
static_reals=[], # 정적 연속형 변수
time_varying_known_categoricals=["month", "is_weekend", "is_holiday", "promotion"], # 미래에도 알 수 있는 범주형 변수
time_varying_known_reals=["price"], # 미래에도 알 수 있는 연속형 변수
time_varying_unknown_categoricals=[], # 미래에 알 수 없는 범주형 변수
time_varying_unknown_reals=["sales", "inventory"], # 미래에 알 수 없는 연속형 변수
variable_groups={}, # 변수 그룹
target_normalizer=None, # 타겟 정규화
add_relative_time_idx=True, # 상대적 시간 인덱스 추가
add_target_scales=True, # 타겟 스케일 추가
add_encoder_length=True, # 인코더 길이 추가
)
# 동일한 정규화 파라미터로 검증 데이터셋 생성
validation_dataset = TimeSeriesDataSet.from_dataset(
training_dataset, val_data, predict=True, stop_randomization=True
)
# 데이터 로더 생성
batch_size = 64
train_dataloader = training_dataset.to_dataloader(
train=True, batch_size=batch_size, num_workers=0
)
val_dataloader = validation_dataset.to_dataloader(
train=False, batch_size=batch_size, num_workers=0
)4.4 TFT 모델 정의 및 훈련
PyTorch Forecasting 라이브러리를 사용하여 TFT 모델을 정의하고 훈련합니다:
# 학습률 모니터링 및 조기 종료 콜백 정의
early_stopping = EarlyStopping(
monitor="val_loss", patience=10, verbose=True, mode="min"
)
lr_monitor = LearningRateMonitor(logging_interval="epoch")
# 로거 정의
logger = TensorBoardLogger("lightning_logs")
# 트레이너 정의
trainer = pl.Trainer(
max_epochs=50,
accelerator="auto", # GPU가 있으면 사용
gradient_clip_val=0.1,
limit_train_batches=50, # 훈련 배치 수 제한
callbacks=[early_stopping, lr_monitor],
logger=logger,
)
# TFT 모델 정의
tft_model = TemporalFusionTransformer.from_dataset(
training_dataset,
learning_rate=0.03,
hidden_size=32, # 은닉층 크기
attention_head_size=1, # 어텐션 헤드 수
dropout=0.1, # 드롭아웃 비율
hidden_continuous_size=16, # 연속형 변수 처리용 은닉층 크기
loss=QuantileLoss(), # 분위수 손실 함수
log_interval=10, # 로깅 간격
reduce_on_plateau_patience=4, # 학습률 감소 전 기다릴 에폭 수
)
# 모델 정보 출력
print(f"Number of parameters: {tft_model.size()/1e3:.1f}k")
# 모델 훈련
trainer.fit(
tft_model,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader,
)4.5 모델 평가 및 예측 시각화
훈련된 모델을 사용하여 예측을 생성하고 시각화합니다:
# 검증 데이터에 대한 예측 수행
predictions = tft_model.predict(val_dataloader)
# 가장 좋은 모델 로드
best_model_path = trainer.checkpoint_callback.best_model_path
best_model = TemporalFusionTransformer.load_from_checkpoint(best_model_path)
# 특정 제품에 대한 예측 결과 시각화
product_id_to_plot = 1
product_data = val_data[val_data["product_id"] == product_id_to_plot]
# 원시 예측 결과 생성
raw_predictions = best_model.predict(
val_dataloader, return_x=True, return_y=True
)
# 예측 결과 시각화
best_model.plot_prediction(
raw_predictions.x,
raw_predictions.y,
raw_predictions.prediction,
idx=0, # 첫 번째 샘플 시각화
add_loss_to_title=True,
)
plt.show()
# 변수 중요도 시각화
best_model.plot_variable_importance()
plt.show()
# 어텐션 가중치 시각화
best_model.plot_attention(
raw_predictions.x,
raw_predictions.y,
raw_predictions.prediction,
idx=0, # 첫 번째 샘플의 어텐션 시각화
)
plt.show()4.6 새로운 데이터에 대한 예측
모델을 사용하여 새로운 데이터에 대한 예측을 수행합니다:
# 새로운 데이터에 대한 예측 예제
def predict_for_new_data(model, dataset, new_data):
# 데이터셋에 맞게 새 데이터 변환
new_data_formatted = dataset.prepare_data(new_data)
# 예측 수행
predictions = model.predict(new_data_formatted)
return predictions
# 새로운 데이터 샘플 생성 (위에서 생성한 데이터의 일부를 사용)
new_data_sample = df[df['product_id'] == 1].tail(max_encoder_length + max_prediction_length)
# 새 데이터에 대한 예측
new_prediction = predict_for_new_data(best_model, validation_dataset, new_data_sample)
# 결과 출력
print("새로운 데이터에 대한 예측 결과:", new_prediction)4.7 모델 저장 및 불러오기
훈련된 모델을 저장하고 나중에 불러와 사용하는 방법:
# 모델 저장
model_save_path = "tft_ecommerce_model.pth"
torch.save(best_model.state_dict(), model_save_path)
# 모델 불러오기
loaded_model = TemporalFusionTransformer.load_from_checkpoint(best_model_path)
# 로드된 모델로 예측
loaded_model_predictions = loaded_model.predict(val_dataloader)
print("로드된 모델의 예측 결과:", loaded_model_predictions[:5])5. 결론 및 TFT 활용 팁
5.1 TFT의 강점 요약
- 다변량 시계열 예측: 여러 변수 간의 복잡한 관계를 모델링
- 해석 가능성: 어텐션 메커니즘과 변수 중요도 분석 제공
- 데이터 유형 구분: 정적, 과거 알려진, 미래 알려진 변수 구분 처리
- 불확실성 정량화: 분위수 예측을 통한 예측 신뢰 구간 제공
- 장기 예측: 장기 의존성 패턴 포착 능력
5.2 TFT 활용 시 주의사항
- 데이터 전처리 중요성:
- 변수 스케일링을 통한 정규화
- 결측치 처리
- 데이터 유형 올바르게 지정
- 하이퍼파라미터 튜닝:
- 은닉층 크기, 어텐션 헤드 수, 드롭아웃 비율 등 조정
- 학습률 스케줄링
- 계산 복잡성:
- 대규모 데이터셋에서 계산 비용 고려
- 배치 크기 및 시퀀스 길이 적절히 설정
- 충분한 훈련 데이터:
- 복잡한 패턴 학습을 위한 충분한 데이터 필요
- 너무 짧은 시계열은 성능 저하 가능성
5.3 TFT의 미래 전망
- 기업 도입 확대:
- 비즈니스 의사결정을 위한 고급 예측 모델로서 활용 증가
- 다양한 산업 분야로 적용 확대
- 기술적 발전:
- 더 효율적인 학습 알고리즘 개발
- 초대규모 데이터셋 처리 최적화
- 다른 모델과의 결합:
- 강화학습, 인과추론 기법과의 결합
- 하이브리드 모델 개발
TFT는 복잡한 시계열 예측 문제에 대한 강력한 솔루션을 제공하며, 해석 가능성을 유지하면서 높은 예측 정확도를 달성하는 혁신적인 모델입니다. 주니어 개발자라면 TFT를 통해 현대적인 시계열 예측 기법을 배우고 다양한 비즈니스 문제에 적용해 볼 것을 권장합니다.
0. TFT의 실제 활용 분야
Temporal Fusion Transformer(TFT)는 다양한 산업 분야에서 시계열 예측 문제를 해결하는 강력한 도구로 활용되고 있습니다. 다음은 TFT의 주요 활용 분야입니다:
0.1 소매 및 전자상거래
- 수요 예측: 제품별, 매장별 판매량 예측을 통한 재고 최적화
- 가격 최적화: 가격 변동에 따른 수요 예측으로 최적 가격 책정
- 프로모션 효과 분석: 마케팅 캠페인의 효과 예측 및 ROI 분석
- 고객 행동 예측: 구매 패턴 분석 및 고객 이탈 예측
0.2 금융 및 핀테크
- 주가 및 자산 가격 예측: 다양한 변수를 고려한 금융 시계열 예측
- 리스크 관리: 불확실성 정량화를 통한 금융 리스크 평가
- 신용 점수 모델링: 시간에 따른 신용 변화 패턴 식별
- 이상 거래 탐지: 비정상적인 금융 거래 패턴 감지
0.3 에너지 및 유틸리티
- 전력 수요 예측: 시간, 날씨, 이벤트 등을 고려한 전력 소비량 예측
- 재생 에너지 생산량 예측: 태양광, 풍력 발전량 예측으로 에너지 그리드 최적화
- 에너지 가격 예측: 시장 변동성을 고려한 에너지 가격 예측
- 설비 유지보수 예측: 장비 고장 시점 예측을 통한 예방적 유지보수
0.4 의료 및 헬스케어
- 환자 상태 예측: 시간에 따른 환자 건강 지표 변화 예측
- 병원 자원 최적화: 병상, 의료진 수요 예측
- 약물 반응 모델링: 시간에 따른 약물 효과 예측
- 전염병 확산 예측: 다양한 변수를 고려한 감염병 확산 패턴 모델링
0.5 공급망 및 물류
- 배송 시간 예측: 다양한 요인을 고려한 배송 소요 시간 예측
- 재고 최적화: 공급망 전체에 걸친 재고 수준 최적화
- 교통 흐름 예측: 실시간 및 장기 교통 패턴 예측
- 운송 수요 예측: 지역별, 시간별 운송 수요 예측
0.6 제조업
- 생산량 최적화: 시장 수요에 따른 생산 계획 최적화
- 품질 관리: 제조 공정 변수와 품질 지표 간 관계 예측
- 설비 성능 예측: 장비 성능 저하 패턴 식별 및 예측
- 원자재 가격 예측: 원자재 비용 변동 예측을 통한 조달 전략 수립
TFT의 가장 큰 장점은 복잡한 시계열 데이터에서 다양한 변수 간의 상호작용을 포착하는 능력과 예측 결과의 해석 가능성을 제공한다는 점입니다. 이러한 특성 덕분에 단순한 예측을 넘어 비즈니스 의사결정에 직접적인 통찰력을 제공하는 도구로 활용되고 있습니다.
'AI 개발' 카테고리의 다른 글
| Cursor에서 Supabase MCP 연동하기 - 자연어로 DB 테이블 생성 (0) | 2025.06.06 |
|---|---|
| 멀티모달 추천 시스템이란? (1) | 2025.05.30 |
| Hugging Face AI Agents 만드는 방법 (허깅페이스 AI 에이전트 개발) (1) | 2025.05.08 |
| 금융 AI : One-Class SVM | 이상거래탐지, 고객이탈예측 (0) | 2025.05.08 |
| 금융에서 사용하는 AI - 이상 거래 탐지 시스템 구현 : Isolation Forest (1) | 2025.05.03 |


